SAP’s samenwerking met Databricks: een gamechanger of niet?
De samenwerking met Databricks is een van de meest opvallende innovaties binnen BDC en biedt veel potentie. Databricks is een absolute leider op het gebied van analytics en beschikt over een breed scala aan geavanceerde data-modelleringsfeatures. Twee belangrijke componenten:
1. Data Integratie:
Dankzij de integratie met Delta Sharing-technologie kunnen SAP-gegevens en niet-SAP-gegevens in realtime gedeeld worden zonder replicatie, wat AI-toepassingen mogelijk maakt. Concreet houdt dit in:
- Toegang tot SAP-gegevens voor AI en machine learning zonder extra dataverplaatsing.
- Integratie met data lakes, wat bijdraagt aan een flexibelere datastrategie.
- Het combineren van SAP-gegevens met externe, ongestructureerde data, wat geavanceerdere analyses mogelijk maakt volgens het Data Lakehouse-principe.
2. Advanced Data features:

Door deze samenwerking is de volledige feature-set beschikbaar op het SAP HANA Cloud-platform. Data-engineers, die gewend zijn te werken met Data Lakehouse, notebooking en version control, zullen blij zijn met deze uitgebreide toolkit.
Data Products: kant-en-klare datasets voor AI en Analytics. Handig?
Een andere belangrijke innovatie binnen BDC is het concept van Data Products. Dit zijn vooraf geconfigureerde datasets die direct inzetbaar zijn voor AI-modellen en rapportages. Hoewel het concept niet nieuw is – denk aan BW Business Content en de Datasphere Marketplace – belooft SAP nu een plug-and–play oplossing, waarbij zelf geen mappings en transformaties nodig zijn.
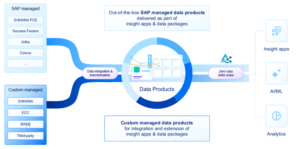
Deze producten zijn volledig SAP managed. We vragen ons op dit moment nog af hoe uitbreidingen die op de business content zijn gedaan hierin worden opgenomen en of dat de extensibility functionaliteiten ook echt goed gaan werken (theorie is vaak anders dan praktijk).
Joule: SAP’s AI Co-pilot
Een andere belangrijke toevoeging binnen de Business Data Cloud is Joule, SAP’s AI Copiloot. Vragen die je aan Joule stelt hebben nu dus niet alleen toegang tot je SAP–data maar maakt het nu ook mogelijk om data uit een gefragmenteerd data landschap (gestructureerde of ongestructureerde databronnen) te combineren. Voorbeeldvragen over klant 360 die dan tegelijk uit meerdere systemen antwoord geven.
De impact
Wat betekent deze verandering concreet? Hoewel er nog meer duidelijkheid moet komen en er meer content zal verschijnen, weten we het volgende:
- Betere AI-integratie: een completer en beter te trainen AI-model dankzij realtime datatoegang over verschillende platformen
- Maturiteit: de combinatie van SAP en Databricks met de bestaande semantische integratie maakt BDC tot een volwassen dataplatform voor SAP-klanten.
- Business model over meerdere systemen (out of the box): waar Business Content voorheen gebaseerd was op één bronsysteem (zoals SAP of Ariba), worden Data Products nu opgebouwd op basis van meerdere systemen.
- Kostenmodel: het prijsmodel blijft een vraagteken. Capacity Units blijven de standaard, wat betekent dat bedrijven moeten opletten voor oplopende kosten.
- Openheid: hoewel SAP claimt een open platform te bouwen, is het nog de vraag hoe makkelijk data naar platforms zoals Azure, Snowflake of Google BigQuery verplaatst kunnen worden.
- Performance: ‘data laten waar het is’ klinkt goed, maar hoe goed blijft de performance als datasets groeien?